The current development in consumer electronics like tablets or mobile phones couldn't be worse.
At least if you care a little bit about privacy. A few years ago, Spy- and Adware that came bundled
with other software was unwelcome to (almost) every Windows user. Internet Discussion Boards were overrun
by people trying to get rid of annoying web browser bars that were installed together with their favorite
file sharing tool. Others even refused to use the Opera web browser because it was ad-sponsored.
Nowadays, we don't have these problems anymore. Spy- and Adware is now socially accepted and more popular than ever before.
Naturally, the name has changed - the euphemism App just sounds cool and innocent.
Many (or even most) Apps for Android or IOS, the two major operating systems found on mobile phones and tablets,
come with some important built-in consumer information right away. To retrieve these ads, an internet connection is needed
because the advertising is tailored specifically for your needs (I know, it's great). Apart from this, an active internet connection
introduces another great field of application. While Ads are transmitted to your device, your personal data may be sent from your device to
trustworthy servers around the world. So it's a win-win situation for everybody - except for you.
The permission concepts of Android and IOS are, of course, completely useless because nobody cares anyway -
"A flashlight app that requires access to Internet, Email accounts and GPS information - seems legit!".
In addition, the modern operating systems are an ideal breeding ground for these privacy nightmare applications because of their standardized
APIs. In contrast to a classical desktop computer system, it's extremely easy to collect data like calender events or Emails
automatically because the APIs already include some ready-to-run methods for these purposes.
However, apart from avoiding this new technology, there isn't that much you can do about the aforementioned issues.
Still, there are ways to figure out which data is sent from and to your device and it's even possible to filter this traffic.
I'll describe on of these ways in the following. But be warned - there's no App for this and you will need a root shell ;)
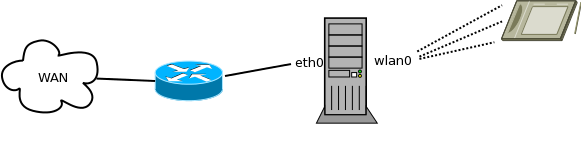
The image describes the basic setup. The PC acts as a Wi-Fi hotspot and forwards the traffic received from a tablet to the
DSL router. To turn the PC into a hotspot, a Wi-Fi USB adapter that can act as a hotspot (iw list |grep AP) is required. Once the adapter is properly
installed on your system, it's easy to create a hotspot with hostapd. The Arch Wiki contains some information
about the configuration, but the default configuration file is quite self-explanatory and just needs a few adjustments. After the setup is done,
brctl (on Debian contained in the package bridge-utils) is used to create a bridge that connects the wireless and the non-wireless network interfaces:
brctl addbr br0
brctl addif br0 eth0
Don't forget to add the correct bridge configuration line in your hostapd.conf:
bridge=br0
After the interfaces are brought up, you may start hostapd:
ip link set dev eth0 up
ip link set dev wlan0 up
ip link set dev br0 up
hostapd -B /etc/hostapd/hostapd.conf
If no errors occurred, you should be able to connect your wireless device to the newly created hotspot. As all traffic now flows through the PC system,
we're able to record and inspect the network packets. tcpdump is the tool of choice for this task:
tcpdump -ni br0 -w tablet.pcap
The command collects all packets passing the bridge interface and writes them to a file tablet.pcap. No need to mention that the command must be run with root
privileges. Once enough packets are collected, the PCAP file can be inspected with Wireshark. Hence we may, for example,
check if the login data for our favorite shopping app is sent via a SSL secured connection or as plain text. As a thorough explanation of Wireshark's
(and tcpdump's) capabilities could easily fill an entire book, I recommend you take a look at the documentation if you're interested in topics like
filter expressions. However, basic knowledge of the TCP/IP protocol suite is mandatory for this.
I've mentioned earlier, that the setup not only allows us to capture all network traffic, but also enables us to filter (and even modify) the traffic.
A few basic firewall rules are enough to stop all communication between the tablet and a specific IP/IP range:
iptables -A FORWARD --dest 192.168.1.0/24 -j DROP
iptables -A FORWARD --src 192.168.1.0/24 -j DROP
In the example, I've used a locally assigned IP address range - in a real world example you would most likely pick a non-private IP. Filtering by IP addresses
however is not always a satisfying solution. Sometimes the packet payload is way more important than the destination or source information. To filter out all
packets containing a specific string like "adserver", iptables' string matching extension is very useful:
iptables -A FORWARD -m string --string "adserver" --algo=kmp -j DROP
For this deep packet inspection, better tools might exist, but I'm not familiar with these (and my iptables skills have also become quite rusty).
All in all, a Linux driven hotspot opens up completely new possibilities when compared to a standard Access Point. Still, inspecting the traffic and
creating proper firewall rules is a very cumbersome procedure.